
PolifonIA.org | Carlos Macías. Con frecuencia las personas integrantes del sector académico se preguntan cuáles serán los recursos de mayor utilidad que la IA estará en condiciones de proveer en el corto y mediano plazo.
Nos enfocaremos aquí en la revisión de aquellas herramientas que se preve puedan tener aplicación extendida en tareas que desarrollan los estudiosos de las Ciencias Sociales y las Humanidades.
Hasta ahora, la expectativa mayor suele centrarse en las herramientas de Inteligencia Artificial que puedan mejorar la metodología de investigación, en calidad y precisión. Tanto en el terreno cualitativo, como en el cuantitativo.
Después de todo, la IA propiciará un uso generalizado en innumerables espacios de la vida personal.
Para imaginar un paralelo cercano, quizá el mejor ejemplo a la vista sea el nacimiento, expansión y vitalidad que pudo alcanzar el internet, en un plazo relativamente corto.
Pero a diferencia de internet -que posibilitó la intercomunicación remota-, la Inteligencia Artificial tendrá una influencia transversal, merced a la propia red global de intercomunicación previamente tendida.
Una influencia que se traducirá en la renovación de las funciones, el trabajo y los procesos de todos los sectores de la actividad productiva y de servicios, de caracter privado y público.
Remontar el periodo de “alucinaciones” IA
A todos nos ha pasado. Solicitamos alguna información a un sistema de IA (o bien, le pedimos crear una imagen o un audio), y en cuestión de segundos recibimos la respuesta.
Nuestra primera reacción es reconocer que la ayuda inteligente es -a más de eficiente- veraz y coherente. Sea ChatGTP o cualquier otro LLM.
En seguida procedemos a analizar con detalle los párrafos de información (de la imagen o el audio) que incluye la respuesta.

No suele resultar extraño que identifiquemos imprecisiones o sesgos en el ágil servicio que nos proporcionó el LLM.
O bien, advertimos que ciertas fuentes de información han resultado poco consistentes con los hechos que conocíamos.
Porque se trata de información que, de alguna manera, hemos desmenuzado por otros medios.
Pues sí, en ese momento nos topamos con lo que se conoce como “alucinaciones” de la IA.
En descargo, debe aceptarse que los propios LLM han asumido las deficiencias presentadas en los últimos tres años.
Por ello producen de modo calendarizado nuevas versiones de sus sistemas generativos de IA.
Alucinantes deficiencias
Las deficiencias se han originado en la fase de entrenamiento de los modelos de datos, que resultaron precoces y defectuosos.
Es evidente que el origen de dichas “alucinaciones” proviene de inferencias érroneas, propias de un diseño algorítmico en proceso de depuración.
Las “alucinaciones” de la IA pueden causar muchos problemas, pero todas son remontables en el diseño.
En especial, en aquellas áreas que requieren de la precisión milimétrica y de la fiabilidad en cada respuesta o en cada modelo predictivo.
En áreas y actividades, por ejemplo, donde está de por medio la vida humana o decisiones que afectan directamente la integridad o los derechos las personas.
Tal es el caso de la salud, la seguridad, la gestión pública, la administración de la justicia, las finanzas y el clima, entre otras.
Menos alucinaciones, mayor adopción
Para tratar de acabar con las hallucinations que socaban la confianza en IA, los ecosistemas mayores han avanzado en la prescripción de protocolos y plantillas.
La idea es garantizar la fundamentación de las fuentes (grounding), y asegurar la cobertura de secciones obligadas en el entrenamiento de cualquier modelo de IA generativa.
Alphabet recomienda incluir en el entrenamiento, entre otros, los siguientes elementos.
- Título
- Introducción
- Cuerpo
- Conclusión.
Con todo, si asumimos la continuidad en el proceso de mejora del entrenamiento de modelos IA, es probable que las cosas se desenvuelvan de la siguiente manera, como parte del crecimiento de la Inteligencia Artificial en 2026.
A finales de este año, casi todos los programas que utilizaremos en nuestros dispositivos contarán con al menos alguna función adicional basada en la Inteligencia Artificial.
Aún más. A finales de 2026, las tareas para diseñar aplicaciones basadas en códigos ya estarán bajo la esfera de IA (no de las personas especialistas). Con la supervisión humana.
De modo que nos encontramos en la fase de creación intensiva de agentes.
Agentes para todos
Diríase que un agente es -valga la simplificación- una especie de paquete de instrucciones complejas y específicas que se dirigen a los sistemas de IA.
Están siendo diseñados para actuar de modo automatizado, con autonomía, a nombre de nosotros. Su diseño incluye las capacidades de razonamiento, planificación y memoria.
En nuestros días, apreciamos que la multiplicación de agentes continúa desatada. Al parecer, Claude (de Anthropic) lleva la delantera.
Cada vez abundan más agentes que se encargan con agilidad de desarrollar tareas de codificación para crear nuevas aplicaciones.
El siguiente esquema nos ayuda a distinguir con claridad la diferencia entre agente, asistente y bot.
Tipo de aplicaciones IA que colaboran en tareas para los usuarios
| Agente de IA | Asistente de IA | Bot | |
|---|---|---|---|
| Objetivo | Realizar tareas de forma autónomay proactiva | Ayuda a los usuarios con las tareas | Automatización de tareas o conversaciones simples |
| Funciones | Puede realizar acciones complejasde varios pasos; aprende y se adapta, y puede tomar decisiones de forma independiente | Responde a solicitudes o instrucciones, proporciona información y completa tareas simples; puede recomendar acciones, pero el usuario toma las decisiones | Sigue reglas predefinidas; aprendizaje limitado; interacciones básicas |
| Interacción | Proactivoy orientado a los objetivos | Reactiva; responde a las solicitudes de los usuarios | Reactivo; responde a activadores o comandos |
Los agentes también harán su fiesta, antes de entrar en razón
Sin novedad. Es previsible que la escena siguiente de la película “inquietud social ante la IA” sea protagonizada por los agentes.
A partir de la creación de Codex AI (mayo 2025), el mayor agente de OpenAI, ha crecido aún más ese género de aplicaciones en diversos ámbitos.
A finales de enero de 2026, la mayoría de los temores provenían del espacio empresarial, por la incursión desaforada de agentes IA, “sin controles de seguridad”.
La compañía Cybersecurity Insiders se refiere a ello como la explotación de puntos ciegos.
Las empresas descubren de repente “herramientas de IA no autorizadas ya operando dentro de sus entornos. Frecuentemente incorporadas con credenciales o acceso elevado al sistema que nadie está monitoreando”.
A decir verdad, hace mucho tiempo que las aplicaciones de innumerables redes sociales y de proveeduría de servicios en línea, conviven con información nuestra en plataformas, cuentas y perfiles.
Por tanto, algún trabajo fuerte en consenso supranacional habrá de realizarse. Se deberá establecer con claridad la línea infranqueable de privacidad en los datos personales y corporativos.
Ello ayudará a realinear de modo normado los propósitos mayores del ecosistema IA.
De dónde son los cantantes
Cuando se habla de software para uso académico, hasta ahora la constante ha sido que grupos de investigadores emprendan la concepción, el diseño y el desarrollo de la paquetería.
Suele ocurrir que, con el tiempo, alguna compañía adquiera los derechos y confiera una visión mayor, más ambiciosa, al desarrollo y la puesta en el mercado del software en cuestión.

El botón de muestra lo vimos aquí en al menos dos artículos anteriores. Así pasó con el Índice Top500 de la Supercomputación y con el leguaje COBOL (1959).
También con la reciente suite australiana Q-CTRL para la navegación cuántica, entre varios ejemplos.
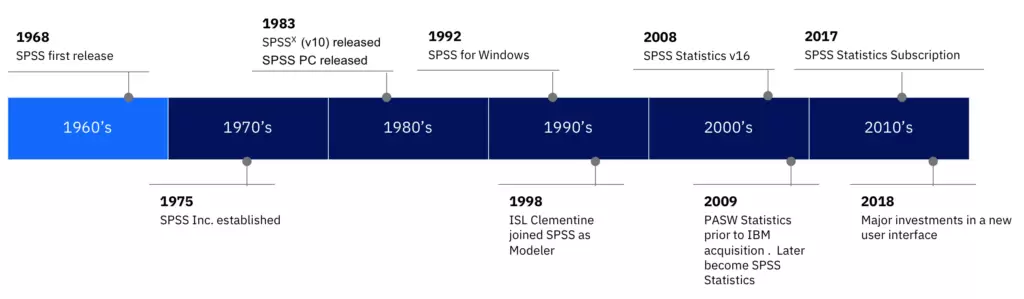
Ahora lo vemos con el SPSS, concebido por profesores de la Universidad de Chicago en 1968, los mismos que hicieron posible su lanzamiento para el sistema operativo de PC en 1984.
Recursos para la metodología cuantitativa
Las necesidades inscritas en el enfoque social de la medición propiciaron el crecimiento de paqueterías encaminadas a respaldar la metodología cuantitativa.
Quizá el programa de mayor consolidación, por su antigüedad, sea el Statistical Package for the Social Sciences, conocido como por sus siglas SPSS.
Se incubó a finales de la década de 1960 en la Universidad de Chicago, pero inició su popularidad ya bien entrada la década siguiente.
La omnipresencia de SPSS
Este programa de Chicago con el tiempo ganó popularidad, en la academia y en los sectores público y privado.
Llegó a ser una herramienta central, para realizar análisis estadísticos, minería de datos, proyecciones y modelos de predicción.
El SPSS terminó en manos de la IBM en 2009. Hablamos justo del periodo en que ocurrió la reconversión de IBM que comentamos en la sección “Los tres dominantes” del artículo anterior (2004-2014).
Por entonces, la IBM vendió sus divisiones de computadoras personales (PC) y de servidores x86 al grupo chino Lenovo.
La IBM prefirió quedarse sólo con las divisiones de servidores y almacenamiento. (Es lider actual en la arquitectura interior de computación de alto rendimiento: supercomputadoras). También se concentró en la proveeduría de servicios y de sotware. En ese contexto adquirió el programa SPSS.
En nuestros días, el IBM SPSS es el paquete de software estadístico dominante. En especial, para las ciencias sociales y la investigación académica (para encuestas, de modo señalado).
Trayectoria de SPSS
El código abierto gana terreno
Le sigue, en orden de empleabilidad, RStudio, que fue adquirido en 2024 por la empresa que promueve el código abierto Posit.
RStudio funciona con código abierto y es gratuito, siempre y cuando sea empleado para propósitos personales y profesionales.
Existen versiones con aplicación empresarial, que tienen costo según el plan a elegir.
Posit puede realizar análisis estadístico y previsualización de datos, pero es importante señalar que requiere ciertos conocimientos para su configuración.
De hecho, RStudio es soportado por el lenguaje R de computación. Ello ha facilitado su transición al modelo conocido como Entorno de Desarrollo Integrado (IDE).
La particularidad del IDE es que permite interactuar con Python y así facilitar su compatibilidad y acceso a IA.
También se impone aludir a Stata; su preferencia se dirige a sectores de dedicados a la economía, las finanzas y la salud pública (particularmente la epidemiología y la demografía).
RStudio y Stata, en pos de la IA
Los tres paquetes referidos antes, como herramientas enfocadas a la metodología cuantitativa, buscan incorporar en su oferta las ventajas potenciales que tendrá su vínculo con la Inteligencia Artificial.
Desde finales de 2025, la IBM ofrece agentes de IA para maximizar el empleo de los datos que se obtienen en SPSS, y así extraer mejores resultados analíticos.
Stata, por su parte, posee cierta ventaja que lo hace más flexible para economistas y epidemiólogos.
Puede transferir datos a Python, lo que en teoría contribuye al mejor procesamiento de datos y a su afinidad, decíamos atrás, con los sistemas de Inteligencia Artificial.

Quizá el mayor atributo de SPSS sea su versatilidad, al crear gráficos accesibles para ser editados y, en su caso, ser publicados.
En cambio, Stata suele dar más trabajo y se deben configurar comandos, para lograr buenos gráficos.
Stata asegura que su sintaxis “es intuitiva y fácil de aprender y enseñar”.
Pero el hecho es que es necesario dominar la sintaxis del comando de gráficos.
Una vez logrado ello, se podrá navegar sin dificultad en el interfaz de Stata, para aprovechar su potencial estadístico.
Tanto el acceso a SPSS como a Stata se realiza mediante la adquisición de licencias institucionales (con un costo considerable).
Aún así, debe decirse que Stata cuenta con opciones un poco más accesibles, para personas que cursan el ciclo universitario.
Como señalamos arriba, PStudio de Posit se cuece aparte, porque se puede descargar e instalar de modo gratuito, si es para trabajo personal y profesional.
El nicho de los justos: código abierto y gratuito
Colocaremos a PStudio o Posit, al lado de WordPress y de Moodle.
WordPress es el mayor Sistema de Gestión de Contenidos (CMS) para internet.
Moodle es el Sistema de Gestión de Aprendizaje (LMS) preferido por las instituciones educativas.
Las tres son plataformas poderosas, confiables y populares, que proporcionan el código abierto, lo que permite su descarga gratuita y la configuración ad hoc.
(Por ejemplo, gracias a WordPress hemos levantado sin costos el presente sitio de polifonia.org).
De Google Forms a QuestionPro
En el frente de batalla cotidiano, para crear formularios y encuestas que recopilan datos, con la inclusión de estadísticas, ya sabemos que contamos con Google Forms.
También suele emplearse para ello QuestionPro, que tiene un potencial mayor. Ofrece la posibilidad de crear una cuenta gratuita.
Puede auxiliarnos en diferentes procesos metodológicos, para crear y aplicar encuestas, obtener una segmentación geográfica y efectuar análisis cualitativo.
Con la cuenta grauita de QuestionPro puedes exportar los datos recabados a Google Sheets y aplicar encuestas sobre un máximo de 20 temas.
La interfaz permite colocar tu logotipo en los cuestionarios en línea.
Está concebido para conducir a los clientes al siguiente paso (el anzuelo IA), para contratar un plan. Resiste, piénsalo dos veces.
Si eludes el anzuelo de contratación, tendrás mayor oportunidad de explorar otras opciones.
QuestionPro fue fundado por un equipo encabezado por Vivek Bhaskaran hace más de 15 años, en Austin, Texas. Bhaskaran nació en la India, pero realizó sus estudios desde muy joven en Estados Unidos.
Egresó de la Universidad Brigham Young (Utah). En fecha reciente, ha llegado a ser columnista y consejero de Forbes.
QuestionPro es una de las compañía más sólidas en cuanto a herramientas de investigación de mercados, pero debe decirse que en sus productos aún no se perciben (a enero de 2026) planes que aseguren la eventual incorporación de aplicaciones IA en su plataforma. Es probable que pronto lo hagan.
Conclusión
Consideramos que continuará el proceso de mejora en el entrenamiento de modelos IA. Se ampliarán las medidas expresas compartidas, como las planteadas por Alphabet (para minimizar las “alucinaciones” de la IA que explicamos al inicio).
Camino al crecimiento de la Inteligencia Artificial en 2026, estimamos que casi todos los programas que utilizamos en nuestros dispositivos contarán con al menos alguna función adicional basada en la Inteligencia Artificial.
A finales de 2026, las tareas para diseñar aplicaciones basadas en códigos ya estarán bajo la esfera de IA (no de las personas desarrolladoras). Con la debida curación de contenidos y edición humana.
Ante la multiplicación de la oferta de aplicaciones IA, nos interesa insistir en la importancia de evitar contratar planes de cualquier tipo en las plataformas existentes. Antes, es necesario que realices una amplia revisión de cada opción.
¿Qué piensas de esta oleda de información IA?
Imagen de la portada: el trabajo cuantitativo en el aula, según Gemini 3.
Fuentes:
Burnam, Lizzy, “15 digital ethnography tools for remote ux research”, en User interviews by user testing, 17 de noviembre, 2013.
Choi, Anna y Katelyn Xiaoying Mei, “What are AI hallucinations? Why AIs sometimes make things up“, en The Conversation, marzo 21, 2025.
Google Cloude, “¿Qué son las alucinaciones de la IA?“, Fundamentar tu IA, s.f.
Kozinets, Robert V., The Field Behind the Screen: Using Netnography For Marketing, Kellogg Graduate School of Management Evanston, IL. (marzo, 2001).










