
polifonIA.org | Carlos Macías. La IA ofrece nuevas posibilidades, con múltiples recursos, para ser aprovechada en las disciplinas de Ciencias Sociales y Humanidades.
A propósito de tales recursos, habíamos preparado un párrafo para el inicio de esta nota. Pero sin duda el párrafo original se quedó muy corto.
En ese párrafo señalamos:
“La nueva HistorIA cuenta ahora con métodos muy eficientes para extraer y transcribir enormes volúmenes de información. No importa si nuestros archivos están almacenados en la nube o en discos”.
Pero -pensándolo mejor- aquí no sólo nos referiremos a la HistorIA.
Lo haremos extensivo a todos los campos del conocimiento a los que pueda resultar útil.
HistorIA y CiencIA
En una entrega anterior, apenas en enero, analizamos las ventajas que ofrece Gemini 3 (Google Cloud Vision) para recuperar y transcribir textos antiguos. PaleografIA Inteligente.
En esa publicación probamos su capacidad con ejemplos documentales de archivos del siglo XVI, en castellano.
Ahora iremos un poco más allá, en busca de mayor capacidad y cobertura para la transcripción.
No todo es OpenClaw.
Un combo IA que sabe conjugar
Lo que vamos a proponer muy probablemente ya lo están probando otros colegas en varios países.
Es seguro que este proceso mejorará y simplificará aún más el manejo y empleo de los grandes repositorios documentales de carácter digital.
Hemos integrado Anthropic con Python 3, para operarlos desde la consola (terminal) de nuestra computadora portátil.
Es decir, hemos podido obtener buenos resultados con la integración de una modalidad de Anthropic (la API) con Python 3, para dirigirlos desde nuestra laptop hacia la carpeta donde suelen residir los archivos voluminosos (Google Drive).
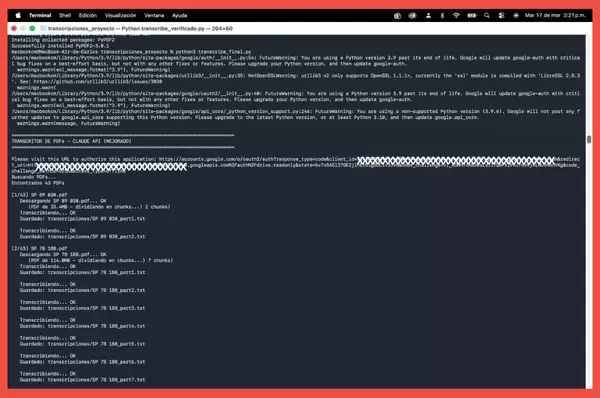
Los archivos .txt van apareciendo y se agrupan en una carpeta especial, creada en nuestra laptop.
Se trata de tres componentes técnicos robustecidos, que juntos crean una pequeña orquesta inteligente, merced a la IA.
El resultado: con esta triada y con las instrucciones de un script, apreciamos con satisfacción cómo se van apilando, uno a uno, como tortillas, en nuestro disco duro, decenas de archivos ya convertidos en formato manejable, editable: .txt.
Es decir, todas las transcripciones que de modo previo solicitamos a Anthropic API, dirigidas a la nube (Google Drive), se fraccionan para su mejor manejo, se auto almacenan en nuestra laptop y se tornan ya editables.
Listas para ser usadas para el mejor propósito.
Tipo de archivos transcritos
Los documentos transcritos residían en archivos considerados “pesados”. Los manteníamos en la nube (Google Drive), para posibilitar su manejo flexible y seguro.
Cada uno de las decenas de archivos pdf alcanzaba entre 300 y 700 MB. Esto es, entre 300 y 600 páginas de texto en imagen original.
Gran parte del contenido de los archivos se había originado en formato pngy jpg. Y, años atrás, lo más que pudimos hacer -por lo laborioso-, fue convertirlos en pdf.
Queremos decir: eran en su origen imágenes de texto antiguo o contemporáneo. Documentos con cobertura temporal del siglo XVI al XX.
La ventaja de Anthropic API, instruido con el scriptpre elaborado en Python 3, es que puede dividir decenas de archivos “pesados” en manejables secciones (con la opción Batch API), y transcribirlas poco a poco, aunque nos demore algunas horas.
Iremos por partes. Regresaremos al proceso de transcripción, para ofrecer detalles del proceso.
¿Perteneces al prototipo de perfil generacional?
Tomemos el caso de la necesidad personal más común.
Tienes almacenado en un repositorio personal gran parte del trabajo de tu vida. Tu esfuerzo está plasmado en decenas de archivos en pdf. Has procurado preservar esos archivos por años.
Quizá tu memoria personal sólo retiene que son muy importantes para tu investigación. Pero es probable que no recuerdes los detalles de su contenido.
Una buena parte de esos archivos pesados (100-600 MB) consiste en gran cantidad de imágenes con texto. Ningún OCR ha podido rescatarlos con decoro, hasta ahora.
Has resguardado tus archivos de forma paciente ya en el enésimo disco externo. Eso sí, bien almacenado en algún cajón, en casa o en oficina.
Hace no muchos años decidiste subirlos a tu cuenta de Google Drive (o a cualquier otra nube), para garantizar su permanencia “en frío”.
Lo mismo guardas ahí textos del siglo XVI que del siglo XX. Documentos relevantes sin duda, capturados alguna vez por la vía del escáner, o con cámara fotográfica, o con algún otro dispositivo móvil.
Por su volumen, después de muchos años, casi has desistido.
No ha resultado accesible extraerlos -ni eficiente-, pero estas segura/o de que merecen ser editados, arreglados, para darles uso pleno.
La alternativa que ofrece la IA
Para lograr la transcripción masiva, lo siguiente sería un paso adelante.
El camino que hemos seguido ha resultado relativamente accesible. El requisito es que estés dispuesta/o a dedicarle algunas horas, con la mayor tranquilidad.
Debemos aceptar, con todo, que estaremos sujetos un poco a la congestión de Claude (Anthropic), pero con la debida paciencia se podrá completar la tarea en horas.
Incluso, para tal congestión existe una salida, con la condición de ser paciente. Sólo elegir la opción más lenta de descarga (Anthropic Batch API). Varias horas de auto descarga, a lo sumo un día.
Eso sí, siempre gastarás menos de lo que cuesta un disco duro de 2TB, sin necesidad de suscripción mensual.
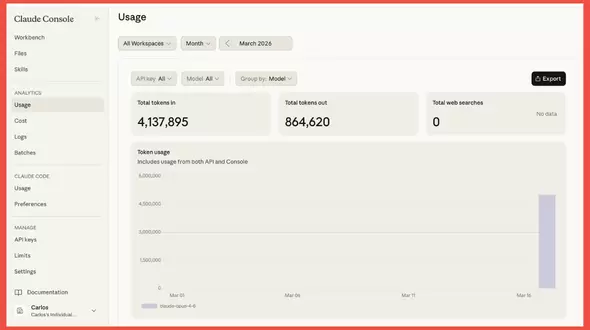
Un apunte necesario: debemos acostumbrarnos al hecho de que el consumo en IA se mide en tokens.
Con el token se tasa la métrica (letras y palabras entregadas) de los modelos de lenguaje generativo de los que hemos escrito en los dos artículos anteriores (LLM). Y estos modelos son justo la IA que conocemos como conversacional, conocida como chatbot.
Se requiere sólo cubrir la cantidad que consumas de tokens, por la transcripción de los archivos solicitados vía API.
El estado de los OCRs
Hasta hace algunos años, el OCR original (Optical Character Recognition) había sido la tecnología dominante, como señalamos en un artículo previo. Convierte imágenes de texto en texto editable. Se originó en la década de 1970.
Hoy en día, se cuenta con soluciones más completas, integradas a la IA, que posibilitan ese trabajo.
No ha sido casual que existan signos de la transición hacia la IA, para el trabajo de recuperación documental de textos para ser editados.
En la acera contraria, uno de los ejemplos dramáticos de esa transición lo muestra el comportamiento decreciente del precio de Adobe en Nasdaq al día de hoy, la emisora cuyo software ha sido por décadas el más socorrido en estas labores: Acrobat.
Recursos tradicionales de transcripción
Poco después del periodo de pandemia, las alternativas de digitalización se multiplicaron.
Hoy existen herramientas eficientes que se apoyan en la IA. Podríamos definirlas como herramientas OCR especializadas.
Algunas de ellas empiezan a aprovechar más los recursos de la IA. Se trata de Mistral, Transkribus, Google Cloud Visión (ahora empleada en Gemini), Tesseract y muchas otras.
| Herramienta | Tipo | Especialidad | Acceso |
| Transkribus | OCR especializado | Manuscritos históricos s. XV-XIX | Freemium + planes académicos |
| Google Cloud Vision | OCR empresarial | Detección automática de idiomas | API de pago |
| Tesseract OCR | Open Source | Textos impresos +100 idiomas | Gratuito (Apache) |
| EasyOCR | Open Source | Deep learning +80 idiomas | Gratuito (Apache) |
| Kraken | Open Source | Manuscritos medievales y modernos | Gratuito (Apache) |
| ABBYY FineReader | Software comercial | Alta precisión +200 idiomas | Licencia de pago |
Recursos IA en pro de la metodología
También son útiles otros recursos de la IA para alcanzar una escala mayor. Se trata de los recursos que inciden en la adopción para la mejora a nivel metodológico. Proveen herramientas que han ido renovando la recolección de datos e información.
Entre ellas, son de destacarse las del siguiente cuadro. (Si deseas un mayor abundamiento al respecto, consulta uno de nuestros artículos previos).
Destaca NotebookLM, sin pago de suscripción, un cuaderno académico que se puede llevar en el celular: ayuda a reunir bibliografía, a concentrar apuntes y a crear resúmenes.
| Característica | NotebookLM | Perplexity AI | QuestionPro AI |
| Enfoque Principal | Análisis profundo de fuentes propias y gestión de conocimiento. | Búsqueda en tiempo real y síntesis de información web. | Investigación de mercados, encuestas y paneles de audiencia. |
| Fuentes de Datos | Documentos personales (PDF, Docs), YouTube y enlaces específicos. | Buscador indexado en tiempo real (300+ fuentes por consulta). | Datos de encuestas, bases de CRM y paneles de consumidores. |
| Funciones Clave | Audio Overviews (podcasts), generación de diapositivas y guías de estudio. | Modo “Deep Research”, buscador Pro y creación de “Pages”. | Diseño de encuestas conversacional y análisis de sentimiento. |
| Colaboración | Notebooks compartidos para equipos de estudio o trabajo. | “Spaces” para proyectos conjuntos con permisos de equipo. | Dashboards de reporte en tiempo real e integración con Slack/Teams. |
| Capacidad Agente | Agentes que actúan como “compañeros de equipo” sobre tus datos. | “Custom Skills” para automatizar flujos de investigación repetitivos. | Simulación de entrevistas con “Digital Twins” de consumidores. |
| Ideal para… | Estudiantes, redactores y análisis de documentos extensos. | Investigadores que necesitan datos actualizados y verificados. | Profesionales de marketing y analistas de experiencia de cliente. |
Procedimiento para la transcripción
Ahora sí, directo a los pasos que deben seguirse para lograr una transcripción masiva.
Desde una laptop. Tomaremos como ejemplo una Mac Air M4.
Requisitos:
- Abre una cuenta en https://console.anthropic.com
- Genera una clave API (se genera gratis, no se necesita suscripción).
- Se agrega un método de pago que pueda cubrir la cantidad esperada. Sólo pagarás los tokens que consumas: en realidad, con 5-25 dólares. (Alrededor de 450 pesos, con el ejemplo de 30 archivos que contienen unas 300 páginas por archivo. No se paga inscripción, ni se requiere estar suscrita/o).
Instalación:
Busca en tu equipo la “terminal” o consola.
En la Mac, teclea la palabra “terminal” en el buscador (Spotlight).
(Si trabajas con Microsoft, tienes Windows Terminal / PowerShell)
La plataforma de Anthropic te dará una API Key.
Al abrir la terminal, escribe el código de abajo. (Sólo sustituye las palabras entre comillas que empiezan con “sk-…”. Ahí inserta la API KEY que obtuviste.)
————
bash
# Abre Terminal en tu Mac
pip install anthropic
------------
# Guarda tu clave API
export ANTHROPIC_API_KEY="sk-ant-..."—————
La API de Claude + Google Drive
¿Cómo funciona?
- Claude conversacional gratuita te indicará cómo configurar tu conexión de Google Drive con OAuth.
- La API Key de Claude (Anthropic) puede acceder directamente a Google Drive vía integración.
- No necesitas descargar nada localmente. (Sólo autorizarla en Google Drive).
- Anthropic procesa ágilmente archivos pdf de hasta 20 MB, por requerimiento en la API estándar.
- Pero en nuestro caso, los archivos son de 100-600 MB. La solución es dividirlos en la nube (con Batch API), no en tu laptop.
Costo estimado de 42 archivos:
- Entre 60 y 130 páginas × 42 archivos = ~2,500-5,460 páginas totales.
- Con OCR + transcripción: ~$15-25 USD (API estándar).
- Entre $7.50 y 12.50 USD (con Batch API, que es más lento, tiene 50% descuento).
Resumen
El flujo recomendado:
- Conectas Claude APIa tu Google Drive.
- Anthropic accede a los pdfdirectamente.
- Para archivos mayores a 20 MB, usas la Batch APIpara dividirlos (crea splits automáticos).
- Los resultados seran: archivos ligeros, editables, los puedes guardar en Google Drive o en una carpeta local.
Puedes auxiliarte en todo momento con la versión de Claude. Es muy eficiente, atenta y puntual, en cada instruccion técnica que te resulte necesaria.
Solicita que te prepare un script, de acuerdo con el número y carácterísticas de tus archivos.
El script lo insertarás en la terminal, para activar las instrucciones y la ejecución del trabajo.
Al final, el flujo de proyecto deberá concluir de la siguiente manera.
- Configuración de Claude API en tu laptop.
- Conexión de Google Drive con OAuth.
- División automática de pdfs grandes.
- Transcripción de documentos antiguos (o textos grandes recientes), de díficil captura.
- Resolución de errores eventuales de sobrecarga.
- Reorganización y culminación del proyecto (con ayuda de Claude gratuito)
- Obtención de la pila de nuevos archivos editables en .txt
Sin duda, podrías toparte con algunos pequeños errores durante el proceso. Lo importante es que la conversación en modalidad gratuita con Claude pueda ayudarte a resolver todas y cada una de las dudas particulares o generales, hasta lograr la transcripción completa.
Esperamos que tengas buenos resultados en el procedimiento de transcripción.
Estamos seguros de que lo terminarás haciendo (y ejemplificando) mejor que nosotros.
Imagen de la portada: Gemini 3. Texto de ayuda para el prompt de la imagen:
“El legado en la era digital”: Académicos latinoamericanos debaten estrategias clave para preservar décadas de investigación ante el impacto de la Inteligencia Artificial. La conservación de archivos digitales valiosos es hoy más crítica que nunca. #IAyAcademia #LegadoDigital #InvestigaciónLatam #PreservaciónDigital










