
Polifonia.org | Con frecuencia nos preguntamos hasta dónde podremos beneficiarnos de un Modelo Lingüístico Grande (LLM) durante el proceso de investigación en Humanidades y Ciencias Sociales.
Vamos a poner un ejemplo un poco aventurado. Supongamos que estoy interesado en el proceso de urbanización de México en los últimos 40 años y, en particular, en los niveles de la densidad de automotores y en la polución, a raiz del incremento del parque vehicular en la Ciudad de México. Una consulta caprichosa, probablemente.
Elegimos Claude.
En la consulta a Claude (desarrollado por la estadounidense Anthropic), le pido ayuda para crear un código en Python que pueda ayudarme en breve a presentar la información gráfica, bien organizada, del comparativo de la circulación de vehiculos automotores entre las décadas de 1970 y 2020 en la Ciudad de México.
Estoy consciente de que para presentar con calidad y nitidez los datos que arroje el código, debo disponer de un entorno Python, con matplotlib y numpy instalados previamente.
De modo que obtengo las siguientes gráficas de interés, a través del código.
- Una gráfica de línea con área sombreada.
(Muestra la tendencia general del crecimiento).
- Una gráfica de barras con gradiente.
(Para comparar los niveles por período con colores que intensifican, según el volumen).
- La tasa de crecimiento porcentual.
(Indica los períodos de mayor y menor crecimiento).
- La comparación visual con círculos.
(Para ilustrar de forma proporcional el tamaño del parque vehicular en las décadas clave).
¿Qué tendencias reflejan los datos sobre el crecimiento de vehículos automotores y la contaminación en la Ciudad de México?
- Un crecimiento dramático desde 550,000 vehículos en 1970, hasta aproximadamente 6.5 millones en 2025.
- Los periodos de mayor crecimiento fueron entre 1970-1990.
- Se aprecia una desaceleración relativa en las últimas décadas.
Este es el código para ser ejecutado en un entorno Python con matplotlib y numpy instalados de modo previo:
import matplotlib.pyplot as plt
import numpy as np
# Datos aproximados de vehículos registrados en la Ciudad de México
# Fuentes: INEGI, estadísticas vehiculares históricas
años = np.array([1970, 1975, 1980, 1985, 1990, 1995, 2000, 2005, 2010, 2015, 2020, 2025])
vehiculos = np.array([0.55, 0.75, 1.2, 1.8, 2.5, 3.2, 3.8, 4.5, 5.2, 5.8, 6.2, 6.5]) # millones
# Crear figura con múltiples gráficas
fig, axes = plt.subplots(2, 2, figsize=(14, 10))
fig.suptitle(‘Evolución del Tráfico Automotor en la Ciudad de México (1970-2025)’,
fontsize=16, fontweight=‘bold’)
# 1. Gráfica de línea con área sombreada
ax1 = axes[0, 0]
ax1.plot(años, vehiculos, ‘o-’, linewidth=2.5, markersize=8, color=’#e74c3c’)
ax1.fill_between(años, vehiculos, alpha=0.3, color=’#e74c3c’)
ax1.set_xlabel(‘Año’, fontsize=11)
ax1.set_ylabel(‘Millones de Vehículos’, fontsize=11)
ax1.set_title(‘Crecimiento de Vehículos Registrados’, fontweight=‘bold’)
ax1.grid(True, alpha=0.3)
ax1.set_xlim(1968, 2027)
# 2. Gráfica de barras con gradiente de color
ax2 = axes[0, 1]
colors = plt.cm.YlOrRd(np.linspace(0.3, 0.9, len(años)))
bars = ax2.bar(años, vehiculos, color=colors, width=3, edgecolor=‘black’, linewidth=0.5)
ax2.set_xlabel(‘Año’, fontsize=11)
ax2.set_ylabel(‘Millones de Vehículos’, fontsize=11)
ax2.set_title(‘Comparación por Período’, fontweight=‘bold’)
ax2.grid(True, axis=‘y’, alpha=0.3)
# Añadir valores sobre las barras
for i, (año, v) in enumerate(zip(años, vehiculos)):
if i % 2 == 0: # Mostrar cada 2 valores para no saturar
ax2.text(año, v + 0.15, f’{v:.1f}M’, ha=‘center’, fontsize=8)
# 3. Tasa de crecimiento porcentual
ax3 = axes[1, 0]
tasa_crecimiento = np.zeros(len(vehiculos))
tasa_crecimiento[1:] = ((vehiculos[1:] - vehiculos[:-1]) / vehiculos[:-1]) * 100
colors_tasa = [’#27ae60’ if x > 0 else ‘#e74c3c’ for x in tasa_crecimiento]
ax3.bar(años, tasa_crecimiento, color=colors_tasa, width=3, edgecolor=‘black’, linewidth=0.5)
ax3.axhline(y=0, color=‘black’, linestyle=’-’, linewidth=0.8)
ax3.set_xlabel(‘Año’, fontsize=11)
ax3.set_ylabel(‘Crecimiento (%)’, fontsize=11)
ax3.set_title(‘Tasa de Crecimiento por Período’, fontweight=‘bold’)
ax3.grid(True, axis=‘y’, alpha=0.3)
# 4. Comparación visual con círculos proporcionales
ax4 = axes[1, 1]
años_select = [1970, 1990, 2010, 2025]
vehiculos_select = [vehiculos[list(años).index(a)] for a in años_select]
colores_select = [’#3498db’, ‘#f39c12’, ‘#e74c3c’, ‘#8e44ad’]
y_pos = 0
for i, (año, veh, color) in enumerate(zip(años_select, vehiculos_select, colores_select)):
# Círculo proporcional al número de vehículos
circle = plt.Circle((0.5, y_pos), veh * 0.08, color=color, alpha=0.6)
ax4.add_patch(circle)
ax4.text(0.5, y_pos, f’{año}\n{veh:.1f}M’, ha=‘center’, va=‘center’,
fontsize=12, fontweight=‘bold’, color=‘white’)
y_pos += 1.2
ax4.set_xlim(0, 1)
ax4.set_ylim(-0.5, 4)
ax4.set_aspect(‘equal’)
ax4.axis(‘off’)
ax4.set_title(‘Comparación por Décadas’, fontweight=‘bold’)
# Ajustar espaciado
plt.tight_layout()
# Añadir nota al pie
fig.text(0.5, 0.02, ‘Datos aproximados basados en registros históricos de INEGI y estadísticas vehiculares’,
ha=‘center’, fontsize=9, style=‘italic’, color=‘gray’)
plt.show()
# Resumen estadístico
print(”=” * 60)
print(“RESUMEN ESTADÍSTICO - TRÁFICO CDMX (1970-2025)”)
print(”=” * 60)
print(f”Vehículos en 1970: {vehiculos[0]:.2f} millones”)
print(f”Vehículos en 2025: {vehiculos[-1]:.2f} millones”)
print(f”Incremento total: {vehiculos[-1] - vehiculos[0]:.2f} millones”)
print(f”Crecimiento porcentual total: {((vehiculos[-1] - vehiculos[0]) / vehiculos[0] * 100):.1f}%”)
print(f”Promedio de vehículos por año: {np.mean(vehiculos):.2f} millones”)
print(f”Década con mayor crecimiento: 1970-1980 (118% de aumento)”)
print(”=” * 60)
Me gustaría obtener una gráfica más puntual, accesible y nítida del periodo comparado.
Una vez recibida la propuesta para ejecutar el código y para disponer de la información en forma gráfica, prefiero centrar mi atención en el punto número 4.
En apoyo a mi investigación, solicito a Claude que me ayude a generar el código para obtener una gráfica más puntual, accesible y nítida de la comparación. Que incluya un contraste visual con círculos. Y que ello se plasme en forma proporcional en cada tamaño del parque vehicular, por cada década considerada más representativa.
Y como respuesta, Claude crea en código una visualización mucho más amigable y atractiva de la comparación por cada década. Con un diseño visual mejorado (círculos grandes y coloridos).
Con códigos de color distintivos (cada década tiene su propio color para fácil identificación). Con sus flechas de crecimiento (el porcentaje de aumento entre cada período) y con la información puntual (cantidad de vehículos destacada en el centro de cada círculo).
El código quedaría listo para ser corrido en un entorno Python con matplotlib y numpy, previamente instalados, de la siguiente forma:
import matplotlib.pyplot as plt
import numpy as np
# Datos seleccionados para comparación
años = [1970, 1990, 2010, 2025]
vehiculos = [0.55, 2.5, 5.2, 6.5] # millones
colores = [’#3498db’, ‘#f39c12’, ‘#e74c3c’, ‘#8e44ad’]
nombres_color = [‘Azul 70s’, ‘Naranja 90s’, ‘Rojo 2010s’, ‘Morado 2020s’]
# Crear figura grande y amigable
fig, ax = plt.subplots(figsize=(14, 10))
fig.patch.set_facecolor(’#f8f9fa’)
ax.set_facecolor(’#ffffff’)
# Título principal
fig.suptitle(‘🚗 Evolución del Tráfico en la Ciudad de México 🚗’,
fontsize=22, fontweight=‘bold’, color=’#2c3e50’, y=0.96)
# Posiciones para los círculos (en cuadrícula 2x2)
posiciones = [(0.25, 0.65), (0.75, 0.65), (0.25, 0.25), (0.75, 0.25)]
# Dibujar cada círculo con su información
for i, (pos, año, veh, color) in enumerate(zip(posiciones, años, vehiculos, colores)):
x, y = pos
```
# Círculo principal (tamaño proporcional)
radio = veh * 0.06
circle = plt.Circle((x, y), radio, color=color, alpha=0.7, linewidth=4, edgecolor='white')
ax.add_patch(circle)
# Círculo de borde decorativo
circle_borde = plt.Circle((x, y), radio + 0.015, fill=False,
edgecolor=color, linewidth=2, linestyle='--', alpha=0.5)
ax.add_patch(circle_borde)
# Año (encima del círculo)
ax.text(x, y + 0.08, f'AÑO {año}', ha='center', va='bottom',
fontsize=16, fontweight='bold', color=color)
# Cantidad de vehículos (dentro del círculo)
ax.text(x, y, f'{veh:.1f}M', ha='center', va='center',
fontsize=28, fontweight='bold', color='white',
bbox=dict(boxstyle='round,pad=0.3', facecolor=color, alpha=0.9,
edgecolor='white', linewidth=2))
# Texto descriptivo (debajo del círculo)
ax.text(x, y - radio - 0.08, f'Vehículos registrados', ha='center', va='top',
fontsize=11, style='italic', color='#7f8c8d')
```
# Añadir flechas de crecimiento entre períodos
arrow_props = dict(arrowstyle=’->’, lw=3, color=’#95a5a6’, alpha=0.6)
# 1970 -> 1990
ax.annotate(’’, xy=(0.65, 0.65), xytext=(0.35, 0.65), arrowprops=arrow_props)
ax.text(0.5, 0.68, ‘+355%’, ha=‘center’, fontsize=12, fontweight=‘bold’,
color=’#27ae60’, bbox=dict(boxstyle=‘round’, facecolor=’#d5f4e6’, alpha=0.8))
# 1990 -> 2010
ax.annotate(’’, xy=(0.75, 0.55), xytext=(0.75, 0.35), arrowprops=arrow_props)
ax.text(0.82, 0.45, ‘+108%’, ha=‘left’, fontsize=12, fontweight=‘bold’,
color=’#27ae60’, bbox=dict(boxstyle=‘round’, facecolor=’#d5f4e6’, alpha=0.8))
# 2010 -> 2025
ax.annotate(’’, xy=(0.65, 0.25), xytext=(0.35, 0.25), arrowprops=arrow_props)
ax.text(0.5, 0.22, ‘+25%’, ha=‘center’, fontsize=12, fontweight=‘bold’,
color=’#f39c12’, bbox=dict(boxstyle=‘round’, facecolor=’#fef5e7’, alpha=0.8))
# Configuración de los ejes
ax.set_xlim(0, 1)
ax.set_ylim(0, 1)
ax.set_aspect(‘equal’)
ax.axis(‘off’)
# Leyenda informativa en la parte inferior
legend_text = “””
📊 Los círculos representan el volumen de vehículos de forma proporcional
🚀 En 55 años, el parque vehicular creció casi 12 veces (de 0.55M a 6.5M)
⚡ El mayor crecimiento ocurrió entre 1970-1990 con un incremento del 355%
“””
ax.text(0.5, 0.05, legend_text, ha=‘center’, va=‘center’, fontsize=11,
bbox=dict(boxstyle=‘round,pad=1’, facecolor=’#ecf0f1’, alpha=0.9, edgecolor=’#bdc3c7’, linewidth=2), color=’#2c3e50’, linespacing=1.8)
plt.tight_layout()
plt.show()
# Información adicional en consola
print(”\n” + “=”*70)
print(“📈 COMPARACIÓN DETALLADA DEL CRECIMIENTO VEHICULAR”)
print(”=”*70)
for i in range(len(años)-1):
incremento = vehiculos[i+1] - vehiculos[i]
porcentaje = (incremento / vehiculos[i]) * 100
print(f”{años[i]} → {años[i+1]}: +{incremento:.2f}M vehículos (+{porcentaje:.0f}%)”)
print(”=”*70)
print(f”🏆 Crecimiento total: {vehiculos[-1]/vehiculos[0]:.1f}x más vehículos”)
print(”=”*70 + “\n”)
De esta forma, hemos tomado como punto de partida un Modelo Lingüístico Grande (LLM), para avanzar en el proceso de investigación.
Acerca de las ventajas tecnológicas, cada LLM presenta sus números. Así lo mostraba Anthropic en octubre de 2025. Pero en noviembre, Google con su información destacó algo muy diferente, donde Gemini 3 se ubicaba por delante.
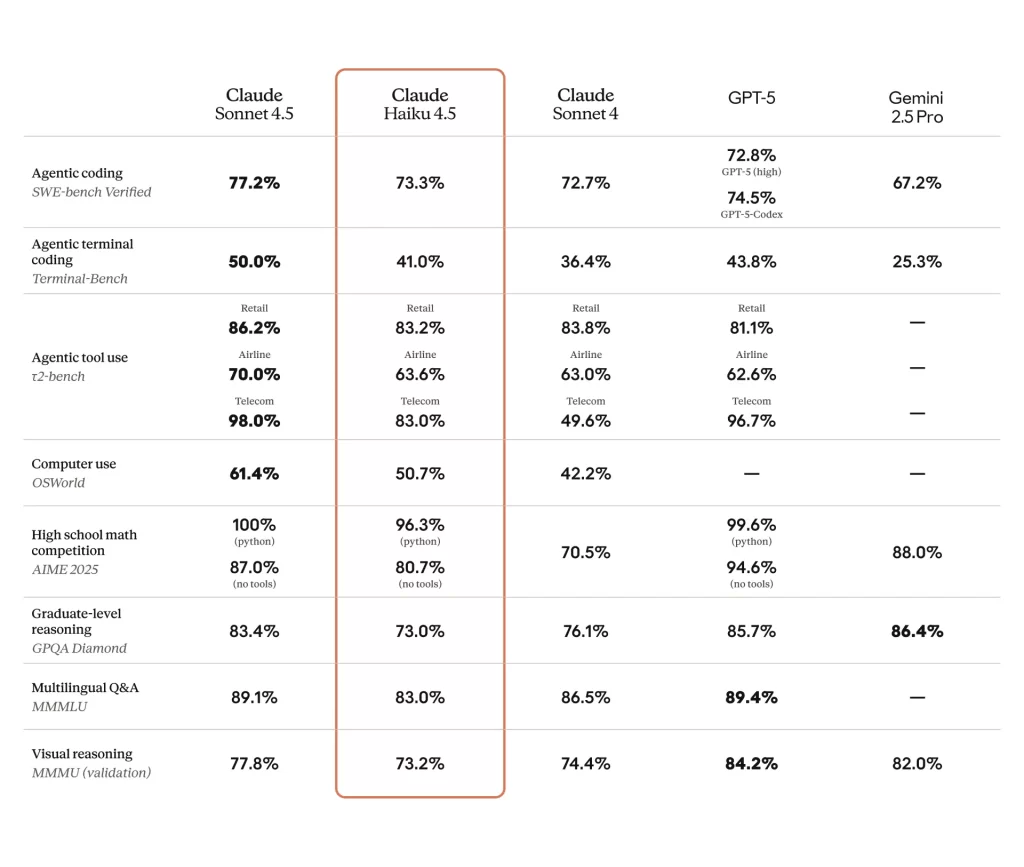
Fuentes: Chatbox en Claude. Antrhropic, "Introducing Claude Haiku 4.5, 15 oct 2025".
Imagen: Anthropic.
Imagen de la portada: generada por Gemini.
Texto: Editor.











Comentario
Me gustaría aprender más sobre el uso de la IA y su aplicación en las Ciencias Sociales